
A gépi tanulás (ML) egy összetett, de logikailag felépített folyamat, amely során a számítógépek megtanulják a mintákat az adatokban, és ezen tudás alapján képesek jóslatokat tenni új, korábban nem látott információkra. Ebben a részletes áttekintésben egy konkrét példán keresztül – mérgező kommentek automatikus felismerése – mutatjuk be a teljes betanítási folyamatot.
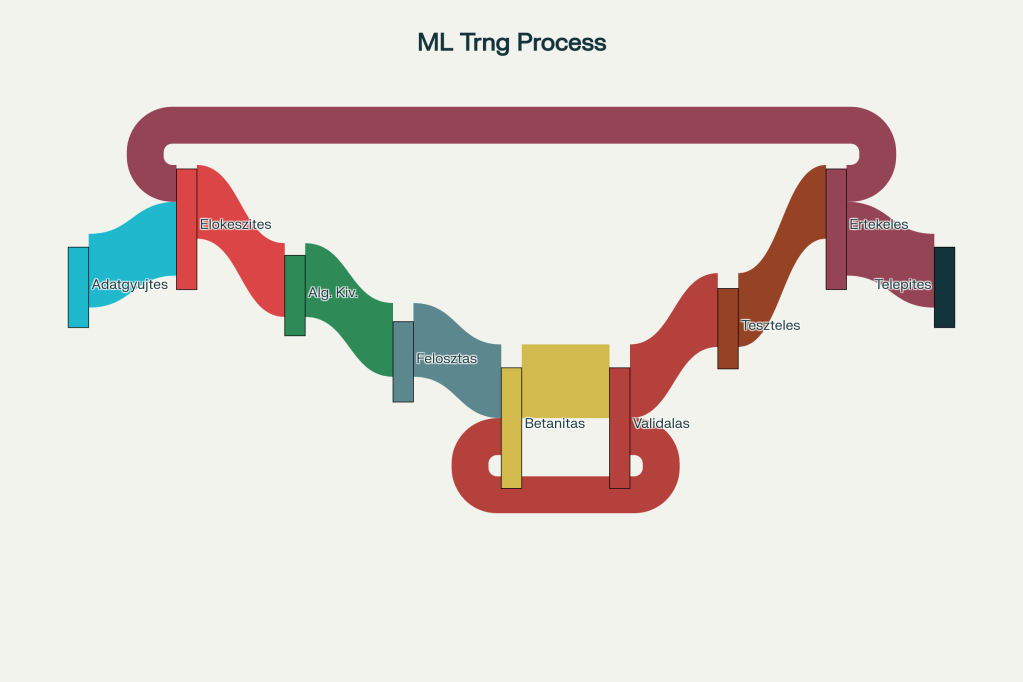
A gépi tanulás betanítási folyamatának lépései
A probléma meghatározása
Mielőtt bármilyen gépi tanulási megoldásba fogunk, alapvető kérdést kell feltennünk: milyen kérdésre keresünk választ? A konkrét példánkban egy weboldalon naponta több ezer hozzászólás érkezik, és szükség van egy automatizált rendszerre, amely kategorizálja a kommenteket és azonosítja a potenciálisan mérgező tartalmakat.
Ez egy tipikus felügyelt tanulási (supervised learning) feladat, ahol címkézett példákat használunk a modell betanításához. A rendszernek meg kell tanulnia megkülönböztetni a “mérgező” és “nem mérgező” kommenteket.
1. Adatgyűjtés
Az első és talán legkritikusabb lépés az adatok beszerzése. Esetünkben ez a weboldalon korábban közzétett hozzászólásokat jelenti. Az adatok minősége közvetlenül meghatározza a modell teljesítményét – ahogy a mondás tartja: “śmét be, szemét ki“.
- Releváns: kapcsolódik a megoldandó problémához
- Hiányzó értékek minimális száma
- Megfelelő reprezentáció az különböző kategóriákból
- Megbízható forrásból származik
2. Adatok előkészítése és tisztítása
A nyers adatok ritkán használhatók közvetlenül a gépi tanulásban. Az előkészítési folyamat több lépést tartalmaz:
Adattisztítás
Címkézés
A felügyelt tanuláshoz címkézett példákra van szükség. Esetünkben minden kommenthez hozzá kell rendelni egy címkét: “mérgező” vagy “nem mérgező”. Ez a folyamat gyakran emberi moderátorok munkáját igényli.
Fontos megjegyzés: Még emberek számára sem mindig könnyű eldönteni, hogy egy hozzászólás mérgező-e. Két moderátornak eltérő véleménye lehet ugyanarról a kommentről, ezért nem várhatjuk el az algoritmustól a 100%-os pontosságot.
3. Algoritmus kiválasztása
A megfelelő algoritmus kiválasztása kritikus fontosságú a sikeres modell építéséhez. Nincs olyan algoritmus, amely minden problémára a legjobb lenne. A választás függ:
- A probléma típusától (osztályozás, regresszió, klaszterezés)
- Az adatok természetétől és mennyiségétől
- A teljesítmény követelményektől
- Az értelmezhetőség fontosságától
Példánkban szöveges osztályozási feladatot oldunk meg, amihez jól használható a Google Cloud AutoML Natural Language vagy más természetes nyelvfeldolgozó algoritmus.
4. Adatok felosztása
A modell helyes tanulásához az adatokat három részre kell osztani:
Adatok felosztása gépi tanulásban
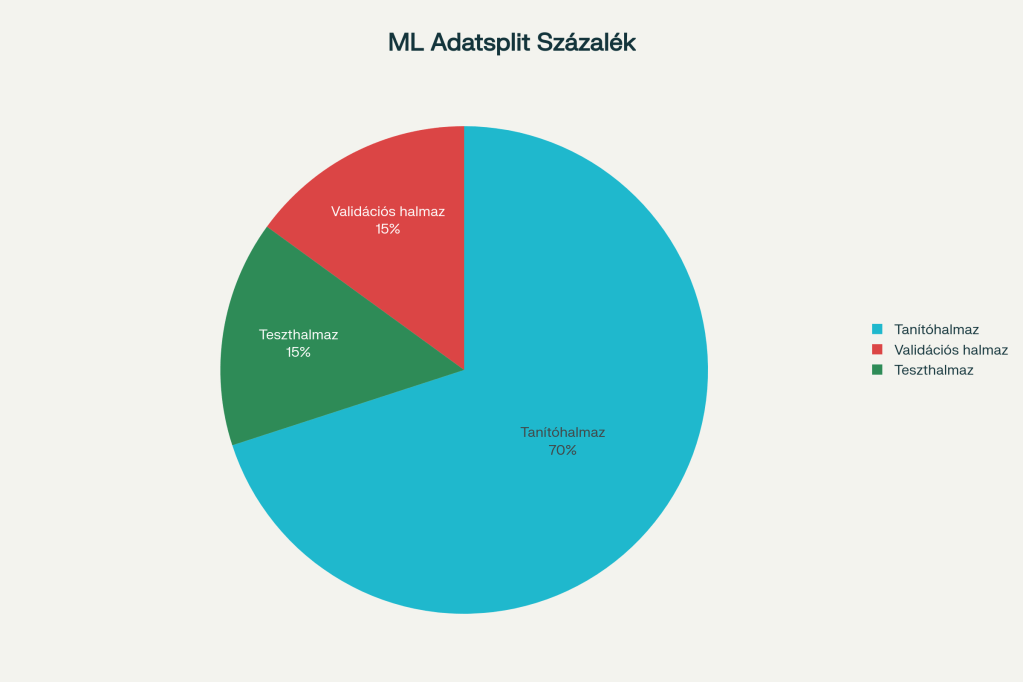
Tanítóhalmaz (Training Set) – 60-70%
Ez az adatrész, amivel a modell “lát” és tanul. Itt ismeri meg a mintákat és összefüggéseket.
Validációs halmaz (Validation Set) – 15-20%
A hiperparaméterek hangolására használjuk. Ez segít megtalálni a modell optimális beállításait és elkerülni a túltanulást (overfitting).
Teszthalmaz (Test Set) – 15-20%
Csak a betanítás után lép a képbe. Olyan adatokon teszteljük vele a modell teljesítményét, amelyeket még soha nem látott.
5. A modell betanítása
A tényleges betanítási folyamat során a modell fokozatosan javítja képességeit. Ez egy iteratív ciklus:
- Adatok bemenet: A modell megkapja a tanítóhalmazt
- Predikció generálása: Tippeket ad a kimenetekre
- Hiba mérése: Összeveti a predikciókat a valós címkékkel
- Paraméterek frissítése: A hibák alapján javítja belső beállításait
- Ismétlés: A ciklus újraindul
A tanulás során a modell egyre pontosabbá válik, ahogy több iteráción megy keresztül.
6. Túltanulás és alultanulás kezelése
Overfitting (Túltanulás)
Akkor fordul elő, amikor a modell túl jól illeszkedik a tanítóadatokhoz, de rosszul teljesít új adatokon. Okai:
Underfitting (Alultanulás)
A modell túl egyszerű ahhoz, hogy megragadja a lényeges mintákat, ezért mind a tanító-, mind a tesztadatokon rosszul teljesít.
7. Modell értékelése
A betanított modellt objektív mérőszámokkal kell értékelni. A legfontosabb fogalmak:
Téves pozitívok (False Positive)
Amikor a modell mérgezőnek jelöl egy valójában ártalmatlan kommentet. Esetünkben ez azt jelenti, hogy egy normális hozzászólást tévesen spam-nek minősít.
Téves negatívok (False Negative)
Amikor a modell nem jelöl meg egy valójában mérgező kommentet. Ez sokkal veszélyesebb, mert a káros tartalom megjelenhet a platformon.
Összefoglaló táblázat – Confusion Matrix
A modell teljesítményét confusion matrix segítségével vizualizálhatjuk:
| Valójában mérgező | Valójában ártalmatlan | |
|---|---|---|
| Mérgezőnek jelölt | Helyes pozitív (TP) | Téves pozitív (FP) |
| Ártalmatlannak jelölt | Téves negatív (FN) | Helyes negatív (TN) |
8. Újságírói és etikai értékelés
A technikai értékelés mellett újságírói és etikai szempontok is fontosak:
- Valóban új információt nyújt-e a modell?
- Mennyire hírértékűek az eredmények?
- Megerősíti-e a meglévő hipotéziseket, vagy új perspektívákat nyit?
- Kinek használ és kinek árthat a rendszer alkalmazása?
Következtetések
A gépi tanulás betanítása strukturált, többlépéses folyamat, amely gondos tervezést és végrehajtást igényel. A kulcsfontosságú tanulságok:
- Az adatok minősége minden másnál fontosabb
- Nincs univerzális algoritmus – minden feladathoz a legmegfelelőbbet kell választani
- A helyes adatfelosztás elengedhetetlen az objektív értékeléshez
- A túl- és alultanulás egyensúlyát kell megtalálni
- Az eredmények kritikus értékelése technikai és etikai szempontból egyaránt szükséges
A gépi tanulás nem varázsütés – egy találgatási folyamat a tanultak alapján, amely hibázhat. A siker kulcsa a folyamat minden lépésének gondos végrehajtása és a megfelelő elvárások kialakítása.
