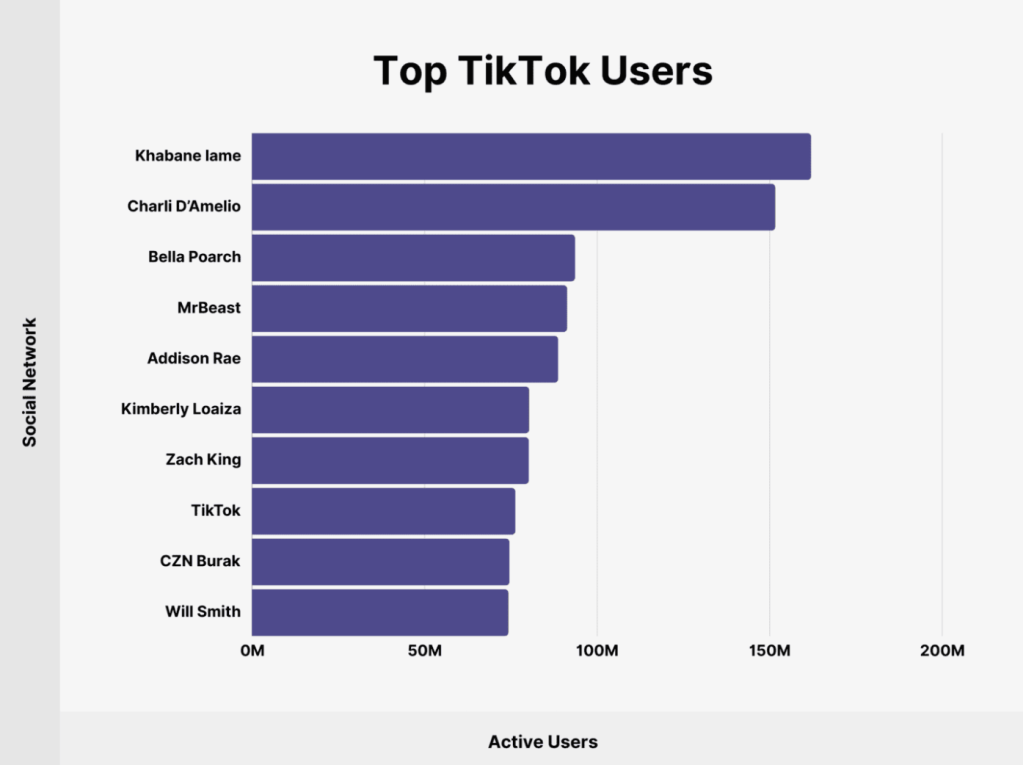
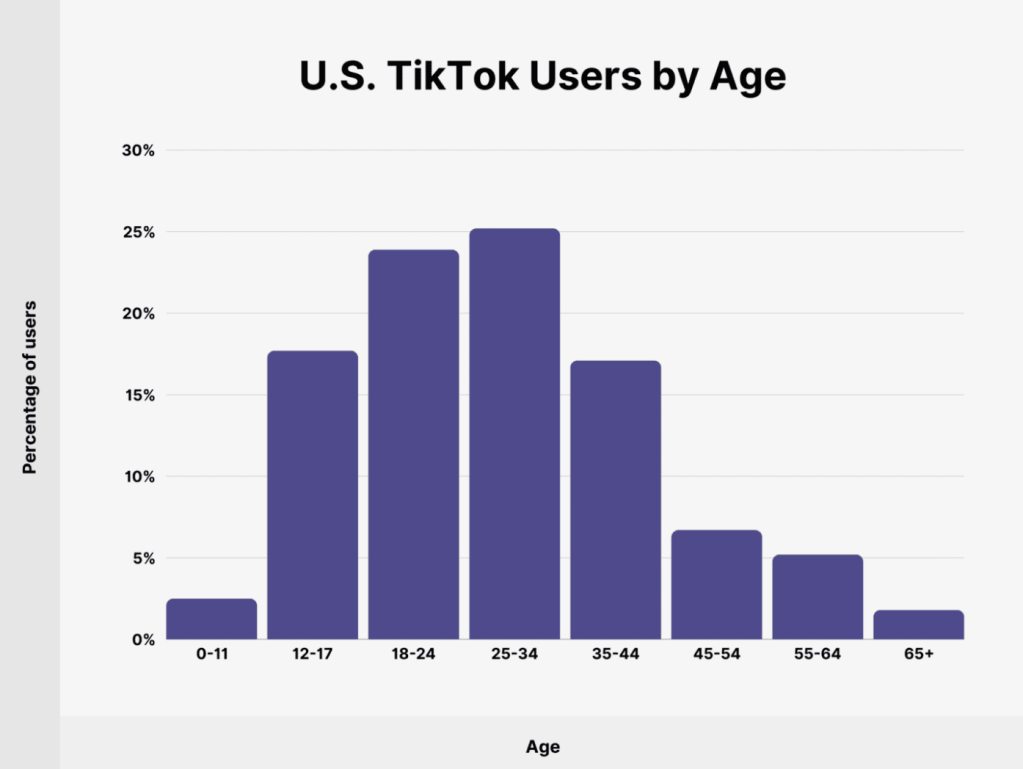
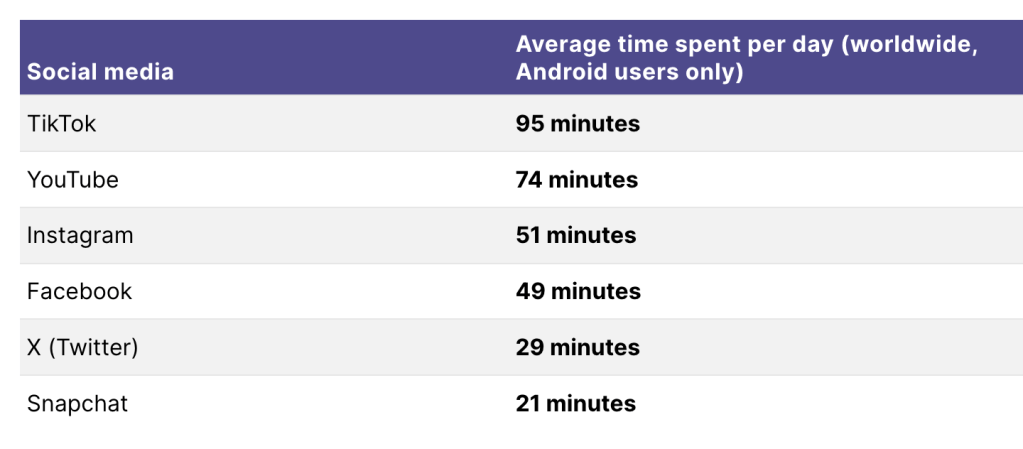
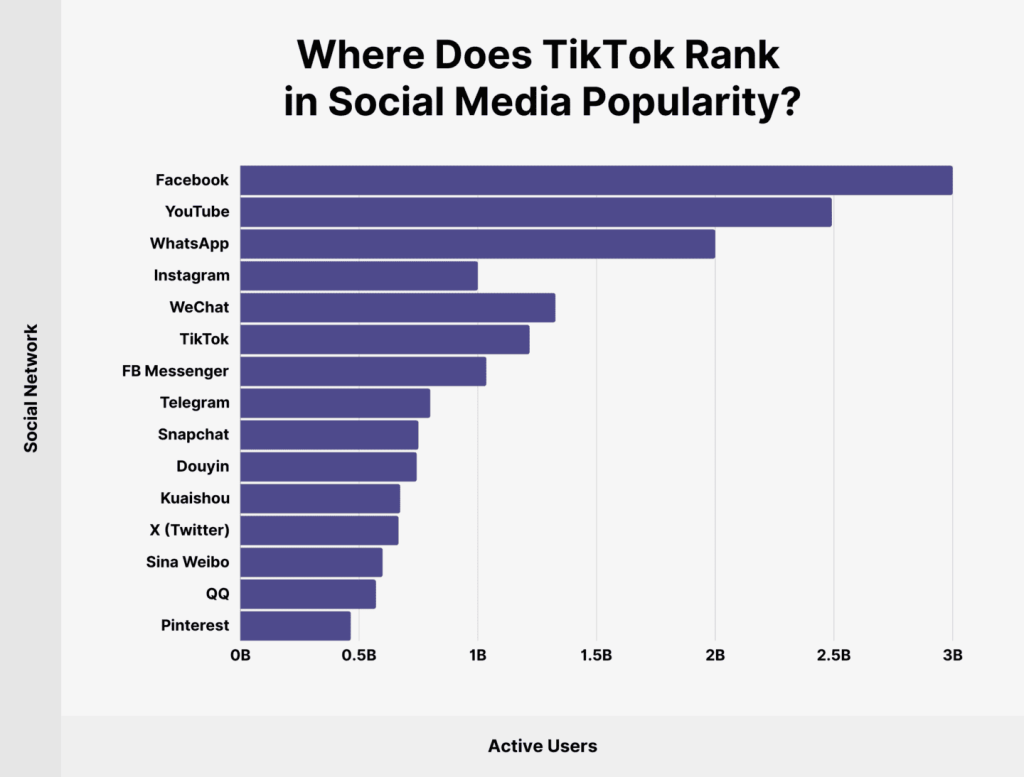
A TikTok számos sikersztorit tud felmutatni, mind a felhasználói, mind a tartalomgyártói oldalon. Az alkalmazás egyik legnagyobb erőssége, hogy lehetővé teszi az ismeretlen tehetségek számára, hogy rövid idő alatt nagy követői bázist építsenek fel és népszerűvé váljanak. Itt van néhány példa:
Zenei Karrierek Indítása: Számos előadóművész számára a TikTok volt az ugródeszka a siker felé. Egyes dalok, amelyek virálissá váltak a TikTokon, hatalmas népszerűségre tettek szert a nagyobb zenei platformokon is, és az előadók karrierjét indították el.
Influencerek és Tartalomgyártók: Sok fiatal influencer és tartalomgyártó vált ismertté a TikTokon keresztül. Az alkalmazás egyedi algoritmusának köszönhetően gyorsan növelhetik követői bázisukat, és ezzel párhuzamosan növelhetik jelenlétüket más közösségi média platformokon is.
Márkák és Marketingkampányok: A TikTok szintén egy népszerű eszköz vált a márkák számára, hogy elérjék a fiatalabb közönséget. Számos márka használta sikeresen az alkalmazást reklámozási célokra, különösen kreatív és interaktív marketingkampányokkal.
Szociális és Kulturális Hatások: A TikTokon terjedő kihívások és trendek gyakran szociális és kulturális hatással bírnak, például társadalmi ügyekre hívják fel a figyelmet vagy új divat- és stílusirányzatokat indítanak.
Edukációs Tartalmak: Az oktatási tartalmak is egyre népszerűbbek a TikTokon. Sok tanár, tudós és szakértő használja az alkalmazást, hogy rövid, érdekes és informatív tartalmakat osszon meg, ezzel is bővítve a platformon elérhető tartalmak körét.
A TikTok egy népszerű videómegosztó közösségi hálózati szolgáltatás, amelyet a ByteDance, egy kínai technológiai cég fejlesztett ki. Az alkalmazást eredetileg 2011-ben alapították, és 2016-ban indították el először Kínában Douyin néven. A TikTok globális verziója 2018-ban vált elérhetővé, miután összeolvadt a musical.ly nevű szolgáltatással.
A TikTok fő célja, hogy lehetővé tegye a felhasználók számára rövid, általában 15 másodperc és 3 perc közötti videók készítését és megosztását. Ezek a videók széles körű tartalmakat foglalhatnak magukban, mint például tánc, szinkronizálás, komédia, és tehetségmutatók. Az alkalmazás különleges jellemzői közé tartoznak a különböző effektek, szűrők és zenei opciók, amelyekkel a felhasználók egyedi és kreatív tartalmakat hozhatnak létre.
A TikTok kiemelkedően népszerű a fiatal generációk körében, és jelentős kulturális befolyással bír világszerte. Az alkalmazás lehetővé teszi a felhasználók számára, hogy kövessék egymást, lájkolják és kommentálják a videókat, valamint cseveghessenek egymással. Emellett a TikTok rendszeresen tart különböző kihívásokat és trendeket, amelyek gyakran virálissá válnak az interneten.
A TikTok egyike a leggyorsabban növekvő és legtöbb letöltést generáló alkalmazásoknak a világon. A szolgáltatás egyre növekvő népszerűsége ellenére számos országban adatvédelmi és biztonsági aggályokat vet fel, és több helyen, például Indiában, már betiltották.
Átlagosan egy nap már Több percig vannak a Tiktok-on mint a Youtube-on!
Kinek szól a tiktok?
A TikTok elsősorban a fiatal generációkhoz szól, különösen a Z generációhoz, amely az 1990-es évek közepétől a 2000-es évek elejéig született fiatalokat foglalja magában. Az alkalmazás nagyon népszerű a tinédzserek és a huszonévesek körében, de egyre több idősebb korosztályú felhasználó is felfedezi magának. A TikTok platformja különféle kreatív és szórakoztató tartalmak megosztására ösztönzi felhasználóit, beleértve a táncokat, vicces videókat, kihívásokat és egyéb kreatív ötleteket.
Az alkalmazás dizájnja és funkcionalitása kifejezetten a mobil eszközökön való könnyű használatra van optimalizálva, amely vonzóvá teszi a fiatalabb generációk számára, akik gyakran mobil eszközöket használnak a szociális média tartalmak fogyasztására. A TikTokon a tartalom gyors, rövid formátumú, és gyakran követi a legfrissebb divatokat és trendeket, amelyek különösen vonzók a fiatalabb korosztály számára.
Ugyanakkor fontos megjegyezni, hogy a TikTok felhasználói bázisa folyamatosan bővül, és egyre több különböző korcsoportú és érdeklődési körű ember csatlakozik a platformhoz. Ezért bár a TikTokot elsősorban fiataloknak tervezték, ma már széles körű felhasználói bázissal rendelkezik, és különböző korosztályok számára kínál szórakozást és kreatív kifejezési lehetőségeket.
Havi aktív felhasználók növekedési rátája az Egyesült Államokban és világszerte A Bytedance anyavállalat szerint a TikTok globális havi felhasználói száma 1157,76%-kal nőtt 2018 januárja óta, amikor 54,7 millió felhasználója volt.
Az Egyesült Államokban az alkalmazás felhasználói száma 2018 és 2023 között 1239,29%-kal nőtt, 11,2 millióról több mint 150 millió aktív felhasználóra emelkedett.
Hivatalos havi aktív felhasználói növekedés (világszerte) A vállalat bejelentései szerint ezek a legfrissebb adatok kiemelik a TikTok 2017 óta bekövetkezett 1157,76%-os növekedését.
szeptember: A TikTok nemzetközi bevezetése.
január: 54 793 729 havi felhasználó. Dec-18: 271 188 301 (394,9%-os növekedés). Dec-19: 507 552 660 (87,2%-os növekedés). Júl: 689,174,209 (35,8%-os növekedés). Szept-21: több mint 1 milliárd felhasználó (45,1%-os növekedés). Hivatalos havi aktív felhasználói növekedés (csak USA) A vállalat amerikai piacra vonatkozó bejelentései szerint ezek a legfrissebb adatok kiemelik a TikTok 1239,29%-os növekedését 2018 óta.
jún. 2020: 91 937 040 (130,4%-os növekedés). Aug 2020: Több mint 100 millió (8,77%-os növekedés).
márc: Több mint 150 millió (50%-os növekedés). Kétségtelen, hogy a Bytedance applikációja szétzúzta, de lenyűgöző, hogy mennyire. A 2016-os indulás óta a TikTok megelőzte ezeket a közösségi hálózati startupokat a havi aktív felhasználók számát tekintve, és ezeknek a srácoknak Hatalmas előnyük volt:
X (korábban Twitter) – 2006-ban indult – 368 millió aktív felhasználó. Reddit- 2005-ben indult – 430 millió aktív felhasználó. Pinterest – 2010-ben indult – 465 millió aktív felhasználó Snapchat – 2011-ben indult – 750 millió aktív felhasználó A TikTok bevételeinek növekedése és mennyi az értéke A TikTok 2022-ben 11,6 milliárd dolláros reklámbevételt hozott, ami a 202-es 3,9 milliárd dolláros bevételhez képest jelentős növekedés, a becsült adatok szerint. A ByteDance (a TikTok tulajdonosa) értékbecslése 2023-ban elérte a 223,5 milliárd dollárt.
A B2B marketingesek számára a LinkedIn a leadgenerálás kulcsfontosságú platformja. Akár olyan taktikákat használ, mint a közösségi értékesítés, a kapuzott tartalom, az InMail vagy a fizetett kampányok, ez a szakmai hálózati platform kulcsfontosságú a potenciális ügyfelekkel való kapcsolatteremtéshez.
Mielőtt azonban új ügyfeleket küldene az értékesítési csapatának, fontos, hogy megbizonyosodjon arról, hogy ezek az ügyfelek minősítettek. A B2B marketingesek többsége arról számol be, hogy az összes leadet eljuttatja az értékesítéshez, annak ellenére, hogy csak körülbelül egynegyedük minősített. Ez a megközelítés rengeteg időt és erőforrást pazarolhat el a csapata számára. Ehelyett szánjon időt a leadek minősítésére:
Megerősítés, hogy a leadek megfelelnek a vevői személyiségnek vagy az ideális ügyfélprofilnak (ICP) – azaz megfelelnek a munkakörnek, a vállalat volumenének vagy méretének, a költségvetésnek és más, a célvásárlót meghatározó jellemzőknek. Növelje annak esélyét, hogy az érdeklődők marketing minősített leadekből (MQL) értékesítési minősített leadekké (SQL) alakulnak át – és végül fizető vásárlókká válnak. Növelje a leadgenerálási erőfeszítései megtérülését (ROI). A potenciális ügyfelek konvertálása a felkutatástól a lezárásig sok erőforrást igényel. Jobb megtérülést érhet el, ha az erőfeszítéseket a minősített leadekre összpontosítja.
Mit kell tennie a leadgenerálási kampány elindítása előtt? Mielőtt erőforrásokat fektetne a LinkedIn leadgenerálásba és -minősítésbe, szánjon időt a megközelítés rendszerezésére. Egy egyszerű rendszer létrehozásával hatékonyabban tudja felülvizsgálni és rangsorolni a LinkedIn-es érdeklődőket.
A vállalkozásának megfelelő leadek megtalálása az ICP meghatározásával kezdődik. Ha még nem dokumentálta ezt az információt, akkor az értékesítési csapatával együttműködve határozza meg az ideális ügyfelet meghatározó kulcsfontosságú jellemzőket. Íme néhány, amit érdemes figyelembe venni:
Munkakör: Milyen szerepet tölt be az Ön ICP-je? A könyvelésben, az értékesítésben, a mérnöki vagy más funkcióban dolgozik? Iparág: Milyen típusú vállalatoknál dolgozik az ICP? Az Ön szervezete pénzügyi, gyártási, logisztikai vagy más iparágban tevékenykedő vállalatoknak értékesít? Munkakör: Milyen munkakörökben dolgoznak a döntéshozói? CXO-k, menedzserek vagy valami más? Szenioritás: Mióta dolgozik az ICP-je az iparágban? C-suite vevőknek vagy belépő szintű ügyfeleknek marketingel? Vállalati méret: Az Ön szolgáltatása vagy terméke kisvállalkozások vagy globális vállalatok számára működik? Mekkora az átlagos létszám? Helyszín: Mi a szervezete szolgáltatási területe? Helyi ügyfelekkel vagy a világ minden tájáról érkező vevőkkel dolgozik? Cégnév: Az Ön szervezete a fiókalapú marketingre (ABM) összpontosít? Lehet, hogy van egy céglistája is, amelyet meg kell céloznia. Költségvetés: Mennyit kell az ICP-jének hajlandónak lennie költeni ahhoz, hogy a csapata ki tudja elégíteni az igényeit? Miután meghatározta az ICP-jét, döntse el, hány négyzetet kell kipipálnia, mielőtt eldönti, hogy egy érdeklődő MQL-e. A fenti jellemzők mindegyikének meg kell felelnie, vagy csak a felének? Ha csak néhány jellemzőnek kell megfelelnie, erősítse meg, hogy valamelyik feltétlenül szükséges-e. Például egy adott költségvetés vagy a vállalat létszáma nem lehet tárgyalhatatlan.
Ezt a keretrendszert szem előtt tartva manuálisan minősítheti az érdeklődőket a LinkedInről gyűjtött információk alapján. Egy másik lehetőség egy harmadik féltől származó ügyfélkapcsolat-kezelő (CRM) eszköz használata az adatok rendszerezésére és a minősített leadek azonosítására.
Ne feledje, hogy a fenti rendszer működhet az MQL-k megtalálására, de ez csak az első lépés a leadminősítési folyamatban. Ahogy értékesítési csapata nyomon követi az MQL-eket, olyan hagyományos keretrendszereket használhat, mint a BANT (költségvetés, hatáskör, szükséglet, idővonal) vagy a CHAMP (kihívások, hatáskör, pénz és prioritás) az SQL-ek azonosítására.
Csak azért, mert az érdeklődők megfelelnek az Ön ICP-jének, vagy bejelölnek bizonyos jelölőnégyzeteket, még nem jelenti azt, hogy mindannyian egyformán fontosak. A legtöbb esetben az értékesítési csapatának egy lead-pontozási rendszert is ki kell dolgoznia, hogy felmérje, mennyire illeszkednek az érdeklődők, és hol tartanak az értékesítési tölcsérben. Így hatékonyan tudják rangsorolni a nyomon követést.
4 natív eszköz a LinkedIn-en történő érdeklődésminősítéshez Bár természetesen használhatsz harmadik féltől származó alkalmazásokat a leadek minősítésére, a LinkedIn számos olyan natív eszközzel rendelkezik, amelyekkel egyszerűsítheted a munkafolyamatokat. Az alábbiakban olyan eszközöket mutatunk be, amelyekkel a céges oldalakon és a személyes profilokon keresztül generálhat és minősíthet leadeket.
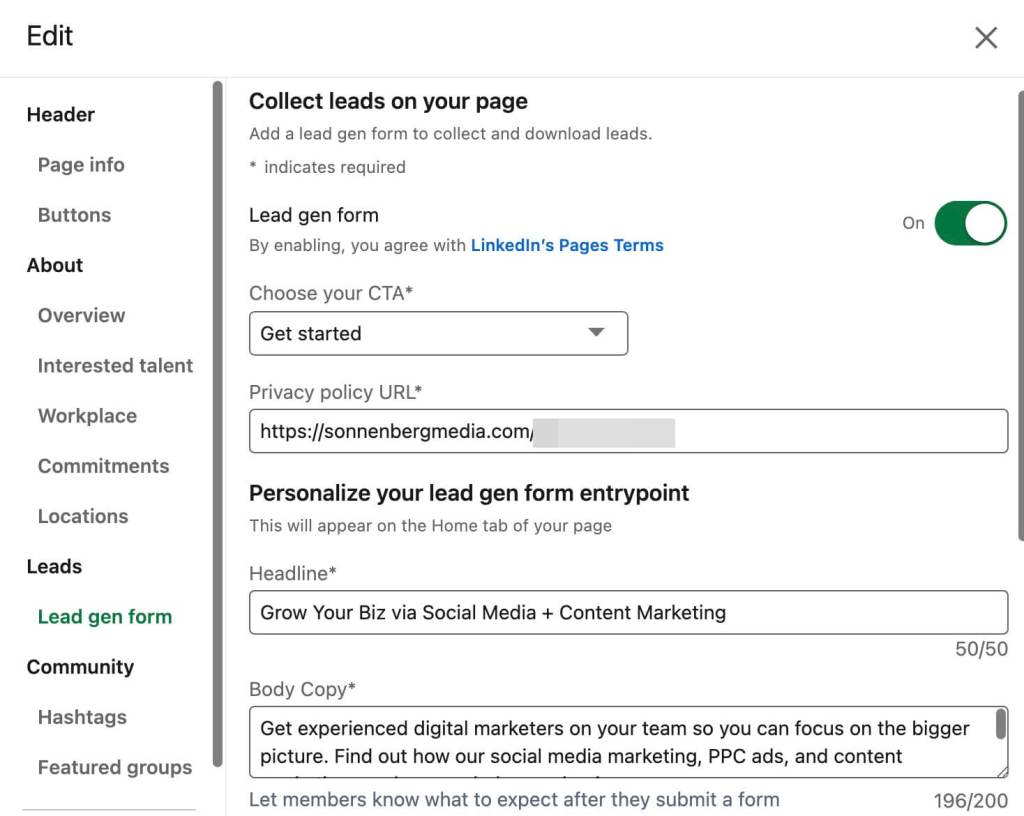
1: Lead Gen űrlap létrehozása
Egy lead gen űrlappal a céges oldaladat arra használhatod, hogy passzívan kapcsolatba lépj az érdeklődőkkel – nincs szükség organikus tartalomra vagy hirdetési kampányokra. Bárki, aki érdeklődik a termékei vagy szolgáltatásai iránt, a vállalati oldaláról kattintva kitöltheti az űrlapot. Mivel az űrlap automatikusan kitöltődik az érdeklődők LinkedIn-profiljának adatai alapján, könnyen láthatja, hogy az érdeklődők megfelelnek-e az Ön ICP-jének.
Ennek a natív űrlapnak a létrehozásához kattintson a LinkedIn vállalati oldalának szerkesztésére, és görgessen le a Lead Gen Form fülre. Kapcsolja be a leadgenerálás opciót, és adjon meg egy linket az adatvédelmi szabályzatára. Válasszon egy olyan cselekvésfelhívást (CTA), amely összhangban van azzal, amit az érdeklődőkkel szeretne, például Kapcsolatfelvétel az értékesítéssel vagy Ingyenes próbaverzió indítása.
Ezután írjon egy olyan címszót (50 karakter), amely felkelti az érdeklődők figyelmét, és kapcsolatfelvételre ösztönzi őket. Ezután használja ki a 200 karakteres korlátot, hogy rövid leírást írjon a vállalat által kínált termékről vagy szolgáltatásról. Adjon okot az érdeklődőknek arra, hogy kitöltsék az űrlapot, és mondja el, mire számíthatnak, ha kitöltötték azt.
Miután beállította az űrlapot, az automatikusan megjelenik a céges oldalán. Az érdeklődőket úgy gyűjtheti be, hogy megnyitja a céges oldalának elemzési lapját, és a menüből kiválasztja a Leads (Vezetők) lehetőséget. Itt letöltheti az űrlapja által generált érdeklődők listáját, valamint az összes automatikusan generált információt az érdeklődők LinkedIn-fiókjából.
Ennek az űrlaptípusnak az egyetlen hátránya, hogy a mezőket nem tudja manuálisan konfigurálni. Ehelyett az űrlap automatikusan összegyűjti az érdeklődők nevét, cégnevét és munkakörének címét. Ritka esetekben ez lehet minden, amire szüksége lehet egy MQL azonosításához. A legtöbb esetben azonban további adatokra lesz szüksége a leadek minősítéséhez.
A legegyszerűbb módja a további minősítő információk gyűjtésének, ha meglátogatja az érdeklődők profilját, akár közvetlenül a LinkedIn-en, akár a közösségi médiaplatform prémium termékében, a Sales Navigatorban. Mindkét platformon felfedezheti a potenciális ügyfelek szerepét és feladatkörét, és a cégoldalukra kattintva többet megtudhat a munkáltatójukról. Ezután a leadminősítő rendszer segítségével a következőképpen értékelheti az érdeklődőket:
Ha úgy tűnik, hogy megfelelnek az Ön ICP-jének, akkor a megosztott elérhetőségeiken keresztül felveheti velük a kapcsolatot. Termékétől vagy szolgáltatásától függően javasolhatja egy értékesítési hívás ütemezését vagy egy demó lefoglalását. Ha egyértelműen nem illeszkednek az ICP-hez, akkor bármikor kizárhatja őket, és úgy dönthet, hogy nem követi őket. Alternatív megoldásként további minősítő kérdésekkel is felveheti velük a kapcsolatot, hogy többet tudjon meg róluk.
2: Ápolja az elkötelezett érdeklődőket
Ha a csapata aktívan használja a LinkedInt közösségi értékesítésre és kapcsolatépítésre, akkor valószínűleg rendelkezik elkötelezett követők hálózatával. A LinkedIn-profilján közzétett, megvalósítható körhinta-posztok vagy inspiráló gondolatvezetés remekül alkalmas lehet arra, hogy értéket nyújtson és megjegyzéseket kapjon a hálózatától. Az ilyen típusú tartalmaknak azonban nehéz új érdeklődőket tulajdonítani.
Az elkötelezett érdeklődők továbblendítése érdekében hozzon létre egy olyan helyet, ahol arra ösztönözheti a nagy érdeklődésű ügyfeleket, hogy azonosítsák magukat, és kezdjenek beszélgetést Önnel. Más szóval, helyezze át a beszélgetést a nyilvános hozzászólásokról a privát DM-ekre, ahol kapcsolatba léphet az érdeklődőkkel, és felteheti a minősítő kérdéseket.
A LinkedIn DM-eken keresztül történő lead-generálás egyik leghatékonyabb módja az, ha exkluzív erőforrást kínál fel. Ahelyett, hogy a hozzászólásokban hivatkozna rá, kérje meg az érdeklődőket, hogy kommenteljenek egy konkrét kéréssel, kulcsszóval vagy emojival. Ezután DM-ezzen azokkal az érdeklődőkkel, akik részt vettek a kérésedben. Ez a megközelítés két okból is működhet. Először is, az érdeklődők kifejezik érdeklődésüket az ajánlatod iránt, ami segíthet a leadek minősítésében. Emellett arra készteti az érdeklődőket, hogy kérjenek Öntől egy DM-et, ami azt jelenti, hogy ténylegesen részt vesznek a beszélgetésben.
Az alábbiakban Ramli John, az Appcues tartalomigazgatója megosztja egy általa összeállított email swipe fájl teaserét. Arra ösztönzi az érdeklődőket, hogy vegyenek részt a posztban, és kommenteljenek egy emojival, hogy kapjanak egy DM-et a leadmágneshez vezető linkkel. Mivel a LinkedIn rendszerint kapcsolatot igényel az üzenetküldés engedélyezése előtt, ez a megközelítés lehetővé teszi Ramli számára, hogy több száz új érdeklődővel lépjen kapcsolatba, és lehetőséget ad arra, hogy a DM-ekben minősítse a leadeket.
Az alábbiakban Mark Kilens, az Airmeet CMO-ja meghívja az érdeklődőket egy exkluzív mesterkurzusra. A poszt felvázolja, hogy az érdeklődők milyen előnyökkel járhat a részvétel, és kiemeli, hogy mi az, ami a számukra kedvező. Ezután arra kéri a leendő résztvevőket, hogy kommentben jelezzék, ha szeretnének egy linket a mesterkurzusra. Miután a beszélgetést DM-ekre terelte, Marknak lehetősége van arra, hogy a LinkedIn-en minősítse az érdeklődőket, vagy e-mailben kövesse nyomon a mesterkurzus résztvevőit.
qualify-leads-on-linkedin6 Ahhoz, hogy a legtöbbet hozza ki ebből a taktikából, tervezze meg a nyomonkövetési sorrendet a LinkedIn-bejegyzés közzététele előtt. A szekvenciád tartalmazhatja annak megerősítését, hogy sikeresen eljutottak az erőforráshoz, majd a leadmágnesre vonatkozó konkrét kérdéseket, végül pedig minősítő kérdéseket tehetsz fel, hogy többet tudj meg a fájdalmas pontjaikról vagy arról, hogy hol tartanak a döntéshozatali folyamatban.
3: Célzott InMail küldése
Ha időt fordított arra, hogy elkötelezett követőtársakat építsen a LinkedIn-en, akkor a fenti megközelítés segíthet abban, hogy elérje azokat az érdeklődőket, akik valószínűleg megfelelnek az ICP-jének. A Sales Navigator segítségével azonban lehetősége van arra, hogy saját listát készítsen az ideális érdeklődőkről, és az InMail segítségével organikusan célozza meg őket.
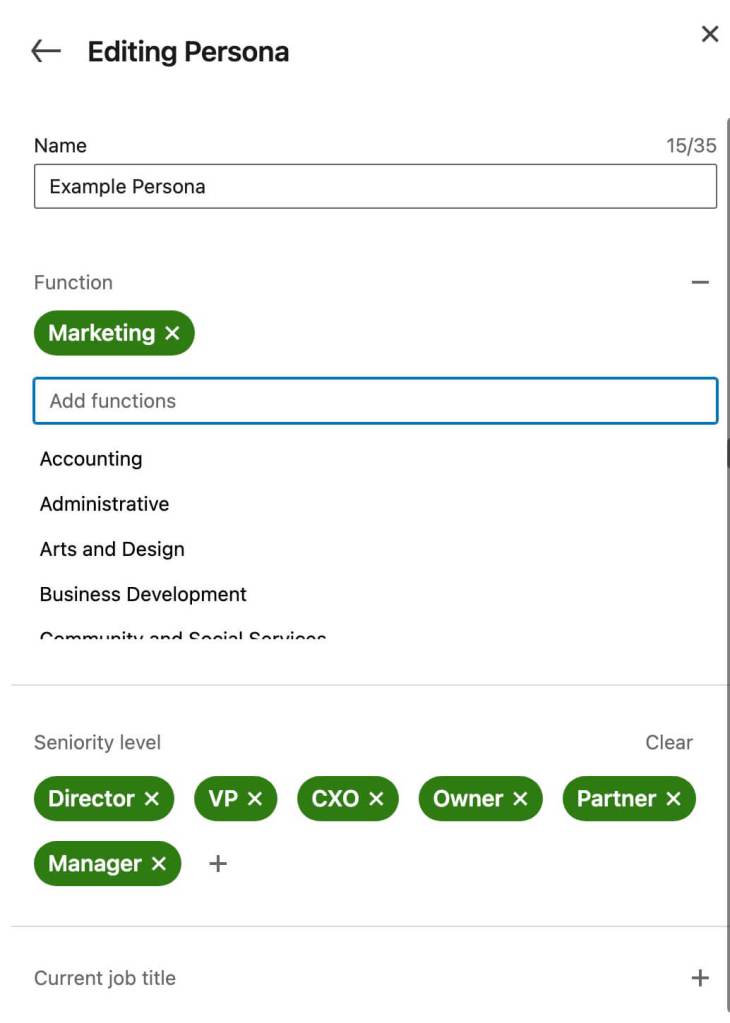
A megfelelő érdeklődők megtalálásához használja a Sales Navigator Persona eszközét, amellyel lényegében felépítheti ICP-jét. Nyissa meg az eszközt, és válasszon a szakmai funkciók, vezetői szintek, munkakörök és földrajzi helyek listájából. Ezután indítson új lead-keresést a Sales Navigatorban, és alkalmazza szűrőként a személyiségét. A keresés pontosabbá tételéhez bármikor hozzáadhat további szűrőket.
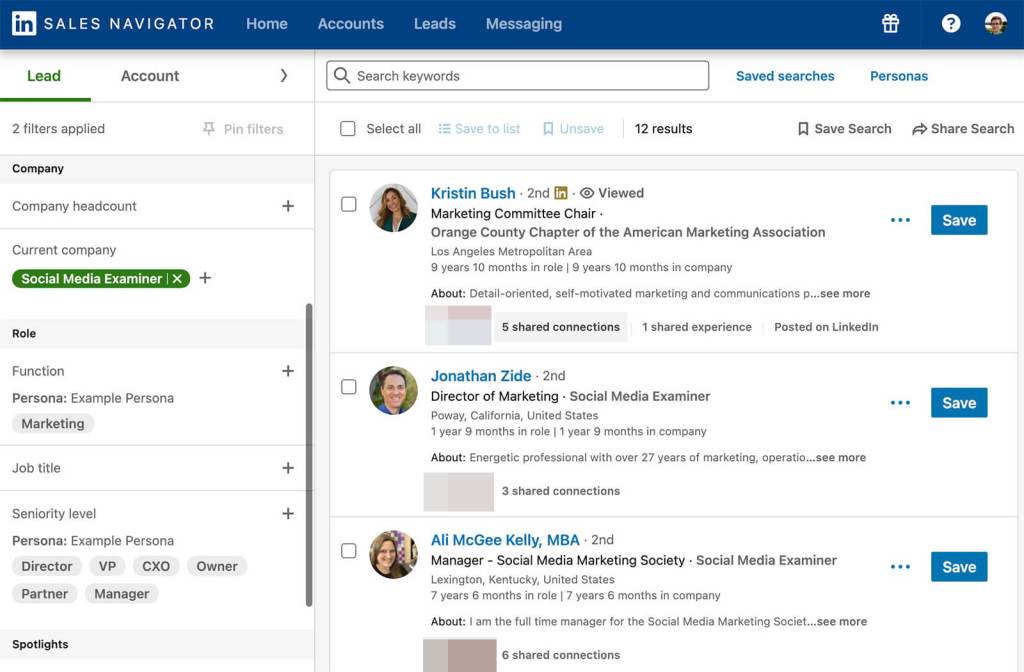
Az alábbi példa egy személyiségszűrőt mutat egy aktuális vállalati szűrővel rétegezve, amely a Social Media Examiner marketingvezetőit és menedzsereit jeleníti meg. A találatok további szűréséhez rákattintva bármelyik tag profilját megtekintheti, és listára mentheti a potenciális érdeklődőket.
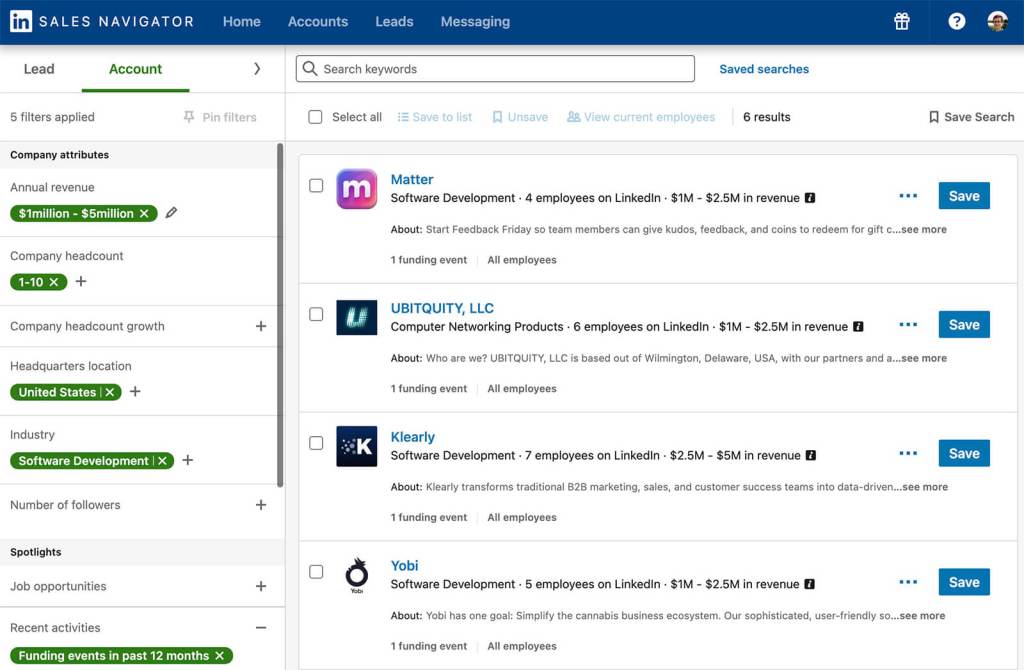
Alternatívaként használhatja a Sales Navigator fiókalapú keresését is, hogy azonosítsa az ideális ügyfélnek megfelelő vállalatokat. Az alábbi példa olyan kis szoftvercégek fiókalapú keresését mutatja, amelyeknek az elmúlt évben sikeres finanszírozási eseményeik voltak.
Bár a fiókalapú keresésekhez nem alkalmazhat személyiségképeket, a mentett fiókok szűrésére használhatja őket. Miután fiókokat vett fel a listájára, nyisson meg egy lead-alapú keresést, és szűrje a személyiségek és a mentett fiókok alapján. Ezután mentse el a releváns döntéshozókat az érdeklődők listájára.
Ezekkel a munkafolyamatokkal rábízhatja a Sales Navigatorra a leadek minősítésének nagy részét. A munkakörök címei, a finanszírozási események, a szándékjelzések és más, a Sales Navigatorból kinyerhető adatok azonban csak ennyit mondhatnak. Ahhoz, hogy megértse, hogy a döntő közönségének valóban vannak-e olyan problémái, amelyeket az Ön vállalkozása meg tud oldani, és hogy megfelelnek-e az Ön termékének vagy szolgáltatásának, beszélnie kell velük.
Más szóval, szükséged van az InMailre, amely a LinkedIn prémium üzenetküldési lehetősége. Az Értékesítési Navigátorból bármelyik érdeklődőnek üzenetet küldhetsz, még azoknak is, akik nem első fokú kapcsolatok. De mielőtt elkezdené a hideg kapcsolatfelvételt küldeni, szüksége van egy forgatókönyvre. Javaslom, hogy kiindulópontként ezt a hideg elérési formulát használd. Ez tömören megkérdezi az érdeklődőket, hogy érdekli-e őket az Ön megoldása, értéket nyújt, és engedélyt kér egy leadmágnes megosztására – anélkül, hogy túlságosan eladósan hangzana.
4: Vezetőgeneráló hirdetések futtatása
Bár a LinkedIn rengeteg lehetőséget kínál a minősített leadek organikus úton történő generálására, érdemes a kampánymenedzserben a fizetett lehetőségeket is felfedezni. Ha leadgeneráló hirdetéseket futtatsz, akkor hagyhatod, hogy a LinkedIn megtalálja a számodra megfelelő közönséget, és automatikusan kezelje a minősítési folyamatot. Mivel testre szabhatja a LinkedIn lead gen űrlapok mezőjét, a cégmérettől kezdve a költségvetési szintig bármit kérhet, bármilyen információt, amire szüksége van az érdeklődő minősítéséhez.
A fizetett taktikákon keresztül történő leadek minősítéséhez nyissa meg a LinkedIn Kampánykezelőt, és hozzon létre egy új kampányt a leadgenerálási céllal. Állítsa be a közönségcélzási beállításokat, és válasszon hirdetési formátumot. A kép- és videóformátumok mellett a lead gen hirdetések támogatják a dokumentumformátumot is, amellyel megoszthatja a lead mágnes előnézeti képét. Az alábbiakban az Extend hirdetés a dokumentum formátumot használja, lehetővé téve az érdeklődők számára, hogy az útmutató több oldalának előnézetét megtekinthessék, mielőtt úgy döntenének, hogy kitöltik a lead gen űrlapot és hozzáférnek a teljes dokumentumhoz.
Hirdetési szinten válasszon egy meglévő posztot, vagy töltsön fel új kreatívokat és szövegeket, amelyek a közönségéhez szólnak. Ezután hozzon létre egy új lead űrlapot a hirdetéshez. A LinkedIn előre beállított űrlapmezői mellett egyéni kérdéseket is hozzáadhat a lead űrlaphoz. Például rákérdezhet a költségvetésre, az időkeretekre és más olyan információkra, amelyekre a leadek minősítéséhez szüksége van.
Bár csábító a lehető legtöbb kérdést feltenni a leadminősítési folyamat automatizálása érdekében, nem szabad túlterhelni az érdeklődőket. A túl sok kérdés arra késztetheti az érdeklődőket, hogy elkattintsanak, még akkor is, ha esetleg megfelelnek az Ön ICP-jének. Ha úgy találja, hogy a LinkedIn leadgenerálási stratégiája nem éri el a konverziós célokat, fontolja meg néhány jelölőnégyzet eltávolítását, hogy az űrlapot könnyebb legyen elküldeni. Ezután manuálisan kövesse nyomon a leadek minősítésének befejezését.
Következtetés A B2B leadek generálása a LinkedIn-en csak az első lépés a megfelelő érdeklődők megtalálása felé. Ha időt szán az organikus vagy fizetett kampányaiból származó leadek minősítésére, biztosíthatja, hogy a megfelelő fiókokat helyezi előtérbe, és növelheti a LinkedIn marketingtevékenységének ROI-ját.
A Gartner előrejelzése szerint 2025-re a vevők és az eladók közötti interakciók 80%-a digitális csatornákon keresztül fog zajlani. Még ha a személyes találkozók vissza is térnek a mezőnybe, aligha kétséges, hogy a képernyőn keresztül történő kapcsolatteremtés tartósan a mesterség szerves része marad.
Hogyan alkalmazkodnak és boldogulnak a modern eladók ebben a környezetben? A megfelelő digitális eszközök sikeres kihasználása alapvető fontosságú. Ezt szem előtt tartva fordultunk ügyfeleink és értékesítési szakértőink közösségéhez, hogy megtudjuk, hogyan használják a LinkedIn-t és a LinkedIn Sales Navigator-t az értékesítők felhatalmazására, a kapcsolatok erősítésére és új értékesítési lehetőségek megszerzésére.
Új döntéshozók kiszűrése. “A Sales Navigator egyik kedvenc felhasználási módja a Mentett keresések funkció volt. Létrehozok néhány nagyon specifikus keresést bizonyos munkakörök és funkciók körül. De nem feltétlenül az azonnal felbukkanó embereket keresem (bár azok is lehetnek jó érdeklődők). Tulajdonképpen az értesítési funkciót használom. Látni akarom, amikor valaki vadonatúj egy döntéshozó pozícióban (például alelnök vagy igazgató), mert akkor nagyszerű jelölt számomra.”
-David J.P. Fisher, elnök, Rockstar Consulting
Számlák feltérképezése és meleg bemutatkozások felszínre hozása. “Mindig meglepődöm, hogy a Sales Navigator mennyire segíti az értékesítési folyamatot. Évekig csak a fejlett keresési képességek miatt használtam a Sales Navot, de az újabb funkciók, amelyek felszínre hozzák a kulcsfontosságú döntéshozókat, a közös öregdiákokat, az ajánlott leadeket, valamint a fióktérkép nagyban felgyorsítják a vásárlási folyamatot iparágtól függetlenül.
Én személy szerint imádom a TeamLink funkciót, mert nincs könnyebb módja annak, hogy valaki elé kerüljön, mint egy meleg bemutatkozás, és arra bátorítom az ügyfeleimet, hogy próbálják ki a TeamLink Extend folyamatot, hogy még több lehetőségük legyen a meleg bemutatkozásra.
És még egy olyan egyszerű dolog is, mint egy olyan feed, amely csak az Ön leadjeiből és fiókjaiból áll, mindig lenyűgözi az ügyfeleimet.”
-Robert Knop, vezérigazgató, Assist You Today
Kapcsolattartás a kulcsfontosságú kapcsolatokkal. “Amikor a LinkedIn Sales Navigator használatát a kapcsolatok erősítésére használjuk, három dolgot mondanék.
Az első az, hogy figyelemmel kísérjük, mit posztolnak az emberek, mit kommentálnak és mit kedvelnek. Ez az egyik dolog, amit az emberek nem használnak ki eléggé: odamehetsz valakihez, ha első- vagy másodfokú kapcsolatban áll, és láthatod, hogy mit posztol, és azt is, hogy mit kedvel. Így részt vehetsz a tartalmaikban, és megmutathatod, hogy támogatod őket, bármit is csinálnak. Nyilvánvaló, hogy ezt sokféleképpen megközelítheted.
Második lehetőség: létrehozok egy Sales Navigator listát azokról az emberekről, akikkel egész karrierem során üzleteltem. Ez lehetővé teszi számomra, hogy nyomon kövessek bizonyos személyeket, akikkel beszélgettem, és így kapcsolatban tudok maradni velük.
A harmadik lehetőség pedig a hangüzenetek és videók használata a kapcsolatok folyamatos építésére és újak létrehozására. Ez egy nagyszerű módja annak, hogy kitűnjünk. Ha nem használja ezt, nagyon bátorítom, hogy tegye meg, mert ez egy jó módja annak, hogy beszélgetést kezdjen.”
-Morgan J. Ingram, az értékesítési képzés és végrehajtás igazgatója, JB Sales Training
A közösségi média, mint az üzleti élet mozgatórugója újragondolása. “A legtöbb szervezet ma már valamilyen formában jelen van a közösségi médiában, de a közösségi médiát taktikusan használják. Ez azt jelenti, hogy a közösségi média költséget (és nem nyereséget) jelent a vállalkozás számára, és kevés versenyelőnyt biztosít.
Ahhoz, hogy a vezetői csapat belássa a közösségi média használatát és összehangolja a megfelelő költségvetési befektetést, közvetlen kapcsolatnak kell lennie a közösségi média és a bevétel, illetve a nyereség között.
Még jobb, ha egy vállalkozás a “közösségi oldalról” átalakulhat az általunk “digitális dominanciának” nevezett állapotba.
A digitális dominancia az, amikor egy vállalkozás felülről vezérelt stratégiával rendelkezik, amely az analóg versenytársak teljes eltörléséhez vezet. Mi így működtetjük az üzletünket.
A LinkedIn Sales Navigator-t nem azért használjuk, mert ez a legjobb leadgenerátor a piacon, hanem mert tudjuk, hogy minden egyes billentyűleütéssel képesek vagyunk a termék használatát profithoz kötni.
De ne felejtsük el, nem elég csak beszerezni a Sales Navigator-t, és máris megtörténik a varázslat, először stratégiára van szükség, és azt is meg kell érteni, hogy mit jelent a közösségi szerepvállalás”.
-Tim Hughes, vezérigazgató és társalapító, DLA ignite
Az érték és a hitelesség előremutatása. “A LinkedIn, valamint a LinkedIn Sales Navigator kritikus eszközzé váltak az eladó sikeréhez egy olyan világban, ahol a személyes és személyes interakciók helyett virtuális értékesítési érintkezési pontok vesznek körül minket. Remélem, hogy mostanra minden eladó felismeri, hogy csak azok teremtenek értéket, akik a lehetséges vevőkkel való virtuális kapcsolattartáson keresztül, hiteles módon, érdekes tartalmakkal
Bár eredetileg filmes és színészi kollektíva volt, az együttes leginkább elektronikus zenéjéről ismert.
Az együttes diszkográfiája tizenkét stúdióalbumból áll.
Történet A GusGus eredetileg 1995-ben alakult filmes és színészi kollektívaként.
Az együttes neve az 1974-es Ali című német filmre utal: Fear Eats the Soul (németül: Angst essen Seele auf) című Rainer Werner Fassbinder filmre, amelyben egy női szereplő kuszkuszt főz a szerelmének, és azt Gusgusnak ejti ki. A GusGus zenéje eklektikus, és bár elsősorban a techno, trip hop és house zenék közé sorolható, a zenekar más stílusokkal is kísérletezett már, és olyan népszerű előadók dalait remixelték, mint Björk, Depeche Mode, Moloko és Sigur Rós.
A zenekar tagsága változatos volt, többek között:
Daníel Ágúst Haraldsson. Emilíana Torrini Davíðsdóttir Magnús Jónsson (más néven Blake) Hafdís Huld Þrastardóttir Urður Hákonardóttir (más néven Föld) Högni Egilsson Birgir Þórarinsson (más néven Biggi Veira vagy Biggo) Magnús Guðmundsson (más néven Maggi Lego, Herb Legowitz, Hunk of a Man, Buckmaster De La Cruz, The Fox, Fuckmaster vagy Herr Legowitz) Stephan Stephensen (más néven President Bongo, Alfred More vagy President Penis) Sigurður Kjartansson (más néven Siggi Kinski) Stefán Árni Þorgeirsson Baldur Stefánsson (a Pénzügyi Művészetek Igazgatója, más néven DJ Tekno Jörgensen) Ragnheiður Axel Páll Garðarsson 1997-ben a zenekar Torontóban lépett fel. Második látogatásukra a Polydistortion című második albumukat támogató turné részeként tértek vissza
1998-ban a “Purple” című szám remixe megjelent Paul Oakenfold Tranceport című trance válogatásán.
A csapat harmadik albuma, a This Is Normal (1999) után a GusGus (Kjartansson és Árni Þorgeirsson) filmes ága kivált, és megalakították a Celebrator nevű produkciós céget, amely ma Arni & Kinski néven ismert, és amely reklámokat és videókat készített.
2004 januárjában Ian Brownnal közösen adták ki a “Desire” című dalt.
A zenekar 2011-ig több mint 700 000 példányt adott el világszerte. A 2015-ös inkarnáció négy tagból áll (President Bongo, Biggi Veira, Urður Hákonardóttir és Daníel Ágúst Haraldsson).
Néhány korábbi tag, mint például Hafdís Huld, Blake és Daníel Ágúst szólóban tevékenykedtek; Emilíana Torrini egy dalt adott Peter Jackson A Gyűrűk Ura című filmjének soundtrackjéhez: A két torony című filmhez.
és a személyes találkozásunk Daniel-el frenetikus volt!